
Understanding Conditional Variance and Conditional Covariance – Towards Data Science
Conditional Variance and Conditional Covariance are concepts that are central to statistical modeling. In this article, we’ll learn what they are, and how to calculate them using a real-world data set. The conditional variance of a random variable X is a measure of how much variation is left behind after some of it is ‘explained away’ via its association with other random variables Y, X, W… etc.
19 Hidden Sklearn Features You Were Supposed to Learn The Hard Way – Towards Data Science
Learn about 19 Sklearn features you have never seen that are direct and elegant replacements to common operations you do manually.
AI Application Development Guide for Business Owners – Becoming Human
Every problem requires a unique solution, even if the company developed similar projects earlier. AI is always unique as it is based on different data and business cases. AI engineers often start the journey by diving deep into the business case and available data, exploring existing approaches and models. AI projects can be classified into four groups: Straightforward projects, well-known technology projects and production projects.
Introducing Mephisto: A new platform for more open, collaborative data collection – Meta AI
Mephisto is a new open, collaborative way to collect, share, and iterate on best practices for collecting data to train AI models. It allows researchers to share novel collection methodologies in an immediately reusable and iterable form. Researchers can swap out components and easily find the exact annotations they need, lowering the barrier for creating custom tasks. Researchers and engineers collecting data across different research domains, crowdsourcing, and server configurations can use the same code to run their tasks.
How to Determine the Best Fitting Data Distribution Using Python – KDnuggets
Distfit is a Python free-form tool that lets you find the best-fit distribution of your data. It attempts to fit the data to 89 different distributions based on an RSS metric. We can then view a visualization overlay of the empirical data and the best fit distribution. The best fit is based on the RSS metric, and the data best fits the normal distribution.
Amazon Comprehend Custom Classification – Towards Data Science
Amazon Comprehend is part of the vast AWS AI/ML stack. It’s the premier Natural Language Processing (NLP) service that AWS offers. In this article we’ll take a sample Spam Dataset and use the Comprehend APIs to launch a Custom Classification training job. Using this we can create an endpoint from our trained Comprehend model that can perform real-time inference.
3 types of data architecture components you should know about; applications, warehouses and lakes – Towards Data Science
3 types of Data Architecture Components You Should Know About: Applications, Warehouses and Lakes. The difference is between applications, data warehouses, and data lakes. The data warehouse is the single version of the truth. Applications are where the data gets generated and the data is defined and structured in the same way. The warehouse is where the application data is brought together and reformatted. Data from the mortgage application is also transferred to the data warehouse.
How to Select Loss Function and Activation Function for Classification Problems – Towards Data Science
Machine learning models consist of mathematical processes that follow a certain flow adaptation. This requires a certain harmony and balance. While the model is being built, the process from importing the data to evaluating the results can take place with tons of different combinations. So, machine learning, especially deep…
What are graph neural networks (GNN)? – Tech Talks
This article is part of a series of posts that (try to) disambiguate the jargon and myths surrounding AI. Graph neural networks (GNN) are a type of machine learning algorithm that can extract important information from graphs and make useful predictions. Graphs are excellent tools to visualize relations between people, objects, and concepts. They are also good sources of data to train machine learning models for complicated tasks.
Python Libraries Data Scientists Should Know in 2022 – KDnuggets
The programming language Python is known to be one of the most accessible programming languages available. Pandas was created by Wes McKinney in 2008, as a Python library for data manipulation and analysis. Matplotlib is a numerical extension of NumPy, which is a cross-platform, data visualization and more. The software includes linear algebra, Fourier transform, and matrix calculation functions.
The 6 Python Machine Learning Tools Every Data Scientist Should Know About – KDnuggets
Machine learning is rapidly evolving and the crucial focus of the software development industry. Businesses from every niche and industry are fast adopting ML to modernize their user interface, security, and AI needs. TensorFlow is a powerful tool for DL and ML, but it does not have a user-friendly interface. Keras tool identifies itself as an API developed for human beings instead of machines.
The “Hello World” of Tensorflow – KDnuggets
TensorFlow is an open-source end-to-end machine learning framework that makes it easy to train and deploy the model. Credit card transactions are subject to the risk of fraud i.e. those transactions are made without the knowledge of the customer. Machine learning models are deployed at various credit card companies to identify and flag potentially fraudulent transactions and timely act on them. We will be using credit card fraud detection data sourced from Kaggle.
Machine Learning Books You Need To Read In 2022 – KDnuggets
Machine Learning has now become a critical element of business functionality in the past few years. Businesses are curious about how implementing technology can benefit them, whilst Machine Learning professionals are eager to learn how far Machine Learning can take us. If you are interested in learning about Machine Learning or want to refine your current skills; I have a list of Machine Learning books you need to read in 2022.
Cross-Validation – Towards Data Science
Machine Learning models aim to predict a value or class from the variables contained in the data. They must be generalist, with the ability to interpret data never seen before and reach an adequate result. Cross-validation is a technique used as a way of obtaining an estimate of the overall performance of the model. There are several Cross-Validation techniques, such as the Holdout, K-Fold and Leave-One-Out.
Deploy a Machine Learning Web App with Heroku – KDnuggets
In a previous blog post, I demonstrated how you can build a machine learning web app in Python using the Streamlit library. The end product looked like this: This is an app that allows users to enter information about their health and lifestyle, and returns an output prediction of how likely the person is to develop heart disease in 10 years. If you’d like to learn more about the model and how the app was built, feel free to go through the tutorial.
The Python Machine Learning Ecosystem – Towards Data Science
6 Python machine learning tools. What are they, and when should you use them?
Python continues to grow as the number one programming language used by data scientists. In Anaconda’s recent State of Data Science in 2021 report, 63% of the data scientists surveyed said that they always or frequently use Python.
German Credit Data (Part 1): Exploratory Data Analysis – Towards Data Science
Data analytics is an important field in data science because it helps businesses optimize their performance. The objective of the German Credit Data is to minimize the chances of issuing risky loans to applicants. An applicant’s demographic and socio-economic profiles are considered by loan managers before a decision is taken regarding his/her loan application. The German Credit data set is a publically available data set downloaded from the UCI Machine Learning Repository.
Teaching Machines with Few Examples – Towards Data Science
Data Scientists often grapple with the question — “How much data do I need?” Intuitively, they understand that more data is better. As a result, they have always tried to get as much data as they could get their hands on or was feasible. Transfer Learning was the first breakthrough that allowed for fewer training data. By leveraging ML models that were trained on a similar task, and customizing the final decision logic on your domain, you could potentially get away with needed a few hundred examples.
Alternative Feature Selection Methods in Machine Learning – KDnuggets
Feature selection methodologies go beyond filter, wrapper and embedded methods. In this article, I describe 3 alternative algorithms to select predictive features based on a feature importance score. These methods are computationally very fast, but in practice they do not render good features for our models. In addition, when we have big datasets, p-values for statistical tests tend to be very small, highlighting as significant tiny differences in distributions that may not be really important.
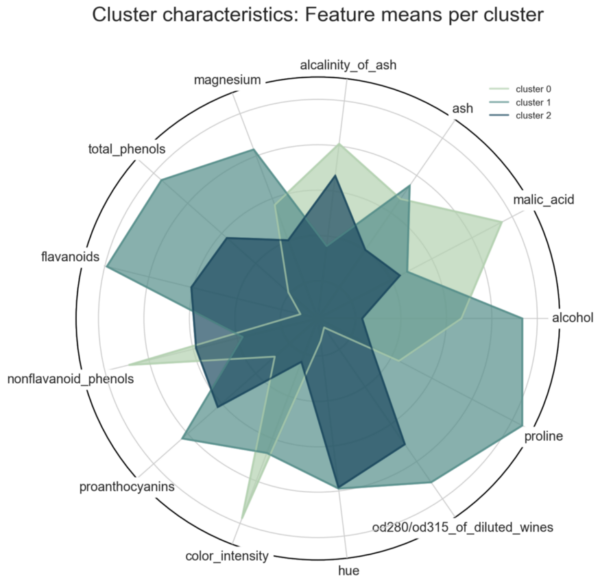
Best Practices for Visualizing Your Cluster Results – Towards Data Science
Clustering is one of the most popular techniques in Data Science. Compared to other techniques it is quite easy to understand and apply. However, since clustering is an unsupervised method, it is challenging for you to identify distinct clusters that are comprehensible to…