

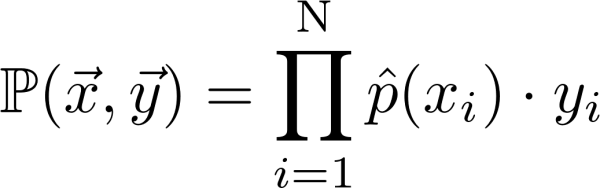
Introduction to Probabilistic Classification: A Machine Learning Perspective
This article walks you through the different evaluation metrics, its pros and cons and optimal model training for multiple ML models. Guide to go from predicting labels to predicting probabilities instead of labels. The model objective is to match predicted probabilities with class labels, i.e. to maximize the likelihood, given in Eq. 1, of observing class labels given the predicted probabilities.
Analyzing Missing Data Problem in Uber Movement Speed Data
We discuss Uber movement speed data, and how to preprocess and analyze it data using Python (Pandas & NumPy).
Uber movement project (http://movement.uber.com/) provides data and tools for cities to more deeply understand and address urban transportation challenges. In terms of data, it shares anonymized data aggregated from over ten billion trips to help urban planning around the world. This post will introduce one important product — speed — for…
Top 5 Free Machine Learning Courses
There is growing demand for machine learning (ML) engineers in the tech industry. Companies are looking for data scientists with machine learning experience, ML engineers, MLOps engineers, and data engineers with a background in developing AI products. Almost all of these courses want you to have experience in Python, Statistics, and Data Science. In this blog, we learn about the top five free machine learning courses.
From Oracle to Databases for AI: The Evolution of Data Storage
Machine learning has become commoditized, but it’s still the Wild West. ML teams across various industries are developing their own techniques for processing data, training models, and using them in production. Over time, these diverse approaches will become standardized. To accelerate that process, the industry needs developer tools designed specifically for AI. In this article, you’ll see the difference between traditional data storage solutions and databases that are built to address AI use cases.
The motivation behind using graph convolutions
Machine Learning with PyTorch and Scikit-Learn is the new book from the widely acclaimed and bestselling Python Machine Learning series. We’ll see why we want to use convolutions on graphs and discuss what attributes we want those convolutions to have. GNNs have evolved “from niche to one of the hottest fields of AI research,” according to the State of AI report from 2021.
StyleGAN 3
Researchers from NVIDIA and Aalto University have released the latest upgrade, StyleGAN 3, removing a major flaw of current generative models and opening up new possibilities for their use in video and animation. The largest model (1024×1024) takes just over 8 days to train on 8xV100 server (at an approximate cost of $2391 on Lambda GPU cloud)
Machine Learning 103: Loss Functions
In two previous articles I covered two of the most basic models used in machine learning. In both cases we were interested in searching for the set of model parameters m that result in the best model predictions d’ of the observed targets d. The quality of a model’s predictions is measured using some loss function L(m) The loss function essentially measures the error between d’ and d’. In general the smaller the value of the loss function, the better the model’s predictions.
Lambda and Scale Nucleus: Empowering Your Model Training with Better Data
Nucleus is a tool from Scale that allows you to visualize and explore your training data. It gives you the tools to explore and understand the relationship between your data and the model predictions that you generate. For this little example we fine tuned a Faster R-CNN to train a neural network for object detection. The example in this post was run on a Lambda Vector workstation running Lambda Stack.
imodels: leveraging the unreasonable effectiveness of rules
imodels: A python package with cutting-edge techniques for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. The package contains implementations of various such methods, including RuleFit, Bayesian Rule Lists, FIGS, Optimal Rule Lists. It is easily installable ( ) and then can be used in the same way as standard scikit-learn models.
Data Mesh & Its Distributed Data Architecture
The enterprise vision to respond faster and deliver superlative customer experience requires an overarching remodeling of data management. The global market size for advanced data management solutions is expected to touch USD 122.9 billion by 2025. The increasing diversity in type and number of data sources continues to obstruct seamless data lifecycle. Going forward, data professionals have found a new way to address the scalability of sources through data mesh.
Using JAX to accelerate our research
JAX is a Python library designed for high-performance numerical computing, especially machine learning research. Its API for numerical functions is based on NumPy, a collection of functions used in scientific computing. Both Python and NumPy are widely used and familiar, making JAX simple, flexible, and easy to adopt. In addition to its NumPy API, JAX includes an extensible system of composable function transformations.
Managing Your Reusable Python Code as a Data Scientist
There are lots of different approaches to managing your own code, which will differ depending on your requirements, personality, technical know-how, role, and numerous other factors. There really is no right or wrong, it’s simply a matter of what works — and is appropriate — for you. Here are a few approaches that I have settled on for managing my own reusable Python code as a data scientist, presented from most to least general code use.