

Advancing first-person perception with 2022 Ego4D challenge
Egocentric Live 4D Perception (Ego4D) aims to train AI to understand and interact with the world like we do, from a first-person (or egocentric) perspective. Meta AI is also releasing EgoObjects, the largest object-centric data set with more than 110 hours of videos and 1.2M object annotations from up to 600 object categories.
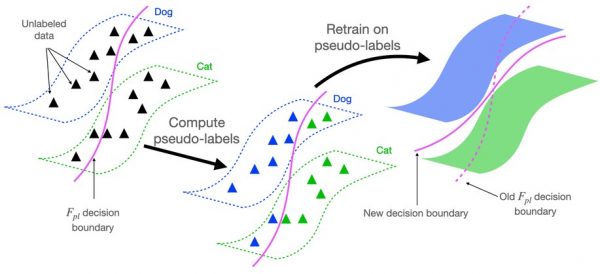
Understanding Deep Learning Algorithms that Leverage Unlabeled Data, Part 1: Self-training
This series of blog posts will discuss theoretical work which seeks to analyze recent empirical methods which use unlabeled data. In this first post, we’ll analyze self-training, which is a very impactful algorithmic paradigm for semi-supervised learning and domain adaptation. In Part 2, we will use related theoretical ideas to analyze self supervised contrastive learning algorithms, which have been effective for unsupervised representation learning.
Improving question-answering models that use data from tables
Question-answering (QA) models sometimes need to retrieve information from tables, which use an entirely different set of semantic cues than free-form text. Historically, most work on table-based QA has concentrated on extracting the contents of a single table cell as the answer to a question. To train t, the model is pretrained on synthetic data before being fine-tuned on a real QA dataset.
Stable learning establishes some common ground between causal inference and machine learning
Causal inference has recently attracted substantial attention in the machine learning and artificial intelligence community. This Perspective clarifies a source of risk for machine learning models and discusses the benefits of bringing causality into learning. We identify the fundamental problems addressed by stable learning, as well as the latest progress from both causal inference and learning perspectives. We discuss relationships with explainability and fairness problems.
Geometry-enhanced molecular representation learning for property prediction
Graph neural networks (GNNs) for molecular representation learning have recently become an emerging research area. They regard the topology of atoms and bonds as a graph, and propagate messages of each element to its neighbours. One obstacle to successful application of GNNs in molecule property prediction is the scarity of labelled data, which is also a common research challenge in natural language processing and computer vision communities.
Design of potent antimalarials with generative chemistry
Recent advances in generative modelling allow designing novel compounds through deep neural networks. Using JAEGER, we designed compounds to inhibit malaria. To prioritize the compounds for synthesis, we used the in-house pQSAR program, a massively multitask bioactivity model based on 12,000 Novartis assays. We selected, synthesized and experimentally profiled two compounds. Both compounds exhibited low nanomolar activity in a malaria proliferation assay and a biochemical assay measuring activity against PI(4)K.
Advances toward ubiquitous neural information retrieval
Information retrieval (IR) is arguably among the most defining challenges of the information age. To excel at this task, an IR system must be able to parse the intricacies and subtleties of human language. Neural models would be the natural solution because of their ability to understand language deeply, but they are not widespread in IR due to computational constraints and scale. New techniques will help pave the way for ubiquitous neural information retrieval.
Unsupervised Skill Discovery with Contrastive Intrinsic Control
Unsupervised Reinforcement Learning (RL) is an emerging paradigm for developing RL agents that are capable of generalization. Competence-based algorithms significantly underperformed other categories. Contrastive Intrinsic Control (CIC) is a new competence-based algorithm that is the first to achieve leading results on URLB. We will demystify what has been holding back competency-based methods.
Pseudo labeling: Speech recognition using multilingual unlabeled data
Meta AI is developing a new high-performance open-source multilingual ASR model that uses pseudo labeling, a popular machine learning technique that leverages unlabeled data. Pseudo labeling aims to solve the same overall challenge: how to make the best use of massive amounts of audio data that has not been transcribed by humans. This work extends pseudo labeling to a multilingual setting where we use a small number of labeled examples to predict labels for an entire data set spanning multiple languages.
When it comes to AI, can we ditch the datasets?
MIT researchers have developed a new way to train machine-learning models to perform image classification tasks. They used synthetic data to train models that can outperform those learned from real data. Using synthetic data also has the potential to sidestep some concerns around privacy and usage rights that limit how some real data can be distributed. A generative model could also be edited to remove certain attributes, like race or gender, which could address some biases that exist.
Bringing practical applications of quantum computing closer
The Annual Conference on Quantum Information Processing (QIP) was held this week. Amazon Web Services is its sole diamond sponsor. Two Caltech professors who are also members of the AWS Center for Quantum Computing are coauthors on six papers at QIP. One paper describes a new method for statistical phase estimation, which could be used to calculate the ground-state energy of a molecule simulated by a quantum computer, among other applications.
Advances in multimodal understanding research at Meta AI
In order for AI to become a more useful tool, it has to learn how to accurately interpret content more holistically. This means working in multiple modalities (such as text, speech, and images) at once. Building the metaverse will require integrating multimodal models with augmented and virtual reality devices, so they can recognize the sound of a siren, for example.