

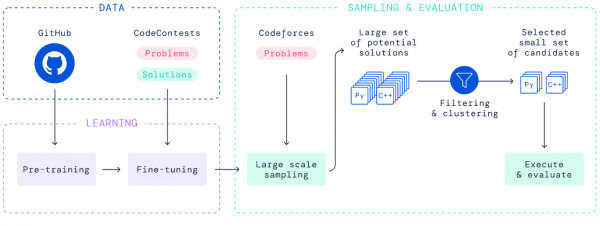
Competitive programming with AlphaCode
AlphaCode achieved an estimated rank within the top 54% of participants in programming competitions by solving new problems that require a combination of critical thinking, logic, algorithms, coding, and natural language understanding. AlphaCode uses transformer-based language models to generate code at an unprecedented scale, and then smartly filters to a small set of promising programs. To help others build on our results, we’re releasing our dataset of competitive programming problems and solutions on GitHub.
Generally capable agents emerge from open-ended play
In recent years, artificial intelligence agents have succeeded in a range of complex game environments. Instead of learning one game at a time, these agents would be able to react to completely new conditions and play a whole universe of games and tasks. DeepMind’s mission of solving intelligence to advance science and humanity led us to explore how we could overcome this limitation to create AI agents with more general and adaptive behaviour.
Technique enables real-time rendering of scenes in 3D
A new technique can represent 3D scenes from images about 15,000 times faster than existing models. The method represents a scene as a 360-degree light field, which is a function that describes all the light rays in a 3D space, flowing through every point and in every direction. The light field is encoded into a neural network, which enables faster rendering of the underlying 3D scene from an image.
Exploring the beauty of pure mathematics in novel ways
Until now, the latest AI techniques have not assisted in significant results in pure maths research. These are the first significant mathematical discoveries made with machine learning, according to the top mathematicians who reviewed the work. We propose a model for how the AI can help at the forefront of pure mathematics, says DeepMind’s Mark Knightley. Knightley: We have discovered a new formula for a conjecture about permutations that has remained unsolved for decades.
Meta-Learning Student Feedback to 16,000 Solutions
A new AI system based on meta-learning trains a neural network to ingest student code and output feedback. Given a new assignment, this AI system can quickly adapt with little instructor work. On a dataset of student solutions to Stanford’s CS106A exams, we found the AI system to match human instructors in feedback quality. This is, to the best of our knowledge, the first successful deployment of machine feedback.
Machines that see the world more like humans do
Computer vision systems sometimes make inferences about a scene that fly in the face of common sense. MIT researchers have developed a framework that helps machines see the world more like humans. The new artificial intelligence system for analyzing scenes learns to perceive real-world objects from just a few images, and perceives scenes in terms of these learned objects. The researchers built the framework using probabilistic programming, an AI approach that enables the system to cross-check detected objects against input data.
Language modelling at scale
Language, and its role in demonstrating and facilitating comprehension – or intelligence – is a fundamental part of being human. It gives people the ability to communicate thoughts and concepts, express ideas, create memories, and build mutual understanding. It’s why our teams at DeepMind study aspects of language processing and communication, both in artificial agents and in humans. Developing beneficial language models requires research into their potential impacts, including the risks they pose.
Our Journey towards Data-Centric AI: A Retrospective
This article provides a brief, biased retrospective of our road to data-centric AI. Our hope is to provide an entry point for people interested in this area, which has been scattered to the nooks and crannies of AI—even as it drives some of our favorite products, advancements, and benchmark improvements. We’re collecting pointers to these resources on GitHub, and plan to write a few more articles about exciting new directions.
Break-It-Fix-It: Unsupervised Learning for Fixing Source Code Errors
Both beginner and professional programmers spend 50% of time fixing code errors during programming. Automating code repair can dramatically enhance the programming productivity. Recent works use machine learning models to fix code errors by training the models on human-labeled (broken code, fixed code) pairs. However, collecting this data for even a single programming language is costly, much less the dozens of languages commonly used in practice.
Automated reasoning’s scientific frontiers
Automated reasoning is the algorithmic search through the infinite set of theorems in mathematical logic. We can use automated reasoning to answer questions about what systems such as biological models and computer programs can and cannot do in the wild. In the 1990s, AMD, IBM, Intel, and other companies invested in automated reasoning for circuit and microprocessor design, leading to today’s widely used and industry-standard hardware formal-verification tools.
Toward speech recognition for uncommon spoken languages
Automated speech-recognition technology has become more common with the most widely spoken of the world’s roughly 7,000 languages. However, these solutions are often too complex and expensive to be applied widely. MIT researchers have developed a new technique that reduces the complexity of an advanced speech-learning model, enabling it to run more efficiently and achieve higher performance. Their technique involves removing unnecessary parts of a common, but complex, speech recognition model and then making minor adjustments so it can recognize a specific language.
Sparsity Without Sacrifice: Accurate BERT with 10x Fewer Parameters
Deep learning is racking up a serious power bill due to the exponentially increasing number of parameters in modern models. How can we take a step towards the brain’s efficiency without sacrificing accuracy? One strategy is to invoke sparsity. In the neocortex, neurons form connections to only a small fraction of neighboring neurons. Sparsity confers at least two important benefits: speed and robustness.
Building Scalable, Explainable, and Adaptive NLP Models with Retrieval
Natural language processing (NLP) has witnessed impressive developments in answering questions, summarizing or translating reports, and analyzing sentiment or offensiveness. Much of this progress is owed to training ever-larger language models, such as T5 or GPT-3, that use deep monolithic architectures to internalize how language is used within text from massive Web crawls. In particular, existing large language models are generally inefficient and expensive to update.
WILDS: A Benchmark of in-the-Wild Distribution Shifts
In real-world applications, distribution shifts are ubiquitous. In medical applications, we might train a diagnosis model on patients from a few hospitals, and then deploy it more broadly to hospitals outside the training set. To be able to reliably deploy ML models in the wild, we urgently need to develop methods for training models that are robust to distribution shifts. ICML 2021 paper presents WILDS, a curated benchmark of 10 datasets that reflect natural distribution shifts arising from different cameras, hospitals, experiments, demographics, countries, time periods, users, and codebases.
Ask a Techspert: What does AI do when it doesn’t know?
Abhijit Guha Roy, an engineer on the Health AI team, and Ian Kivlichan, a Jigsaw engineer, talk about using AI in real-world scenarios. They discuss the importance of training AI to know when it doesn’t know when faced with the unknown. Rare conditions, while individually infrequent, might not be so rare in aggregate.
How to Improve User Experience (and Behavior): Three Papers from Stanford’s Alexa Prize Team
In 2019, Stanford entered the Alexa Prize Socialbot Grand Challenge 3 for the first time. Chirpy Cardinal won 2nd place in the competition, with a modular design that combines both neural generation and scripted dialogue. We used this setting to study three questions about socialbot conversations: What do users complain about, and how can we learn from the complaints to improve neurally generated dialogue? What strategies are effective and ineffective in handling and deterring offensive user behavior?
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Imitation Learning is a promising approach to endow robots with various complex manipulation capabilities. By allowing robots to learn from datasets collected by humans, robots can learn to perform the same skills that were demonstrated by the human. However, a lack of open-source human datasets and reproducible learning methods make assessing the state of the field difficult. The study analyzes the most critical challenges when learning from offline human data for manipulation.
MuZero: Mastering Go, chess, shogi and Atari without rules
The ability to plan is an important part of human intelligence, allowing us to solve problems and make decisions about the future. MuZero uses a different approach to overcome the limitations of previous approaches. Instead of trying to model the entire environment, MuZero just models aspects that are important to the agent’s decision-making process. After all, knowing an umbrella will keep you dry is more useful to know than modelling the pattern of raindrops in the air.
Building architectures that can handle the world’s data
A 2D residual network may be a good choice for processing images, but at best it’s a loose fit for other kinds of data. Dealing with more than one kind of data, like the sounds and images that make up videos, is even more complicated and usually involves complex, hand-tuned systems built from many different parts. As part of DeepMind’s mission of solving intelligence, we want to build systems that can solve problems that use many types of inputs and outputs.
Simulating matter on the quantum scale with AI
Erwin Schrödinger proposed his famous equation governing the behaviour of quantum mechanical particles. Applying this equation to electrons in molecules is challenging because all electrons repel each other. Now, in a paper (Open Access PDF) published in Science, we propose DM21, a neural network achieving state of the art accuracy on large parts of chemistry. To accelerate scientific progress, we’re also open sourcing our code for anyone to use.